Introduction
Over ten years ago, React rethought best practices for the world of client-rendered SPAs.
Today, React is at peak adoption, and continues receiving healthy doses of criticism and skepticism.
React 18, alongside React Server Components (RSCs), marks a significant phase shift from its original tagline as “the view” in client-side MVC.
In this post, we’ll attempt to make sense of React’s evolution from React the library to React the architecture.
The Anna Karenina principle states, “all happy families are alike, where each unhappy family is unhappy in its own way.”
We’ll start by understanding the core constraints of React and the past approaches to managing them, exploring the underlying patterns and principles that unite happy React applications.
By the end, we’ll understand the changing mental models found in React frameworks like Remix and the app directory in Next 13.
Let’s start by understanding the underlying problems we’ve been trying to solve up until now. This will help us contextualize the recommendation from the React core team to use higher-level frameworks with React, that have tight integrations between server, client, and bundler.
What problems are being solved ?
There’s usually two types of problems in software engineering: technical problems and people problems.
One way to think about architecture is as a process of finding the right constraints over time which help manage these problems.
Without the right constraints that address people problems - the more people collaborate, the more complex, error-prone, and riskier changes become as time rolls on. Without the right constraints for managing technical problems - the more you ship, the poorer the end-user experience usually becomes.
These constraints ultimately help us manage our biggest constraint as humans building and interacting with complex systems - limited time and attention.
React and people problems
Solving people problems is high leverage. We can scale the productivity of individuals, teams, and organizations with limited time and attention.
Teams have limited time and resources to ship fast. As individuals, we have limited capacity to hold large amounts of complexity in our heads.
Most of our time is spent figuring out what’s happening, and what’s the best way to change or add something new. People need to be able to operate without loading up and holding the entire system in their head.
A big part of React’s success is how well it managed this constraint compared to existing solutions at the time. It allowed teams to go off and build decoupled components in parallel that can declaratively compose back together and “just work” with a unidirectional data flow.
Its component model and escape hatches allowed for abstracting away the mess of legacy systems and integrations behind clear boundaries. However, one effect of this decoupling and component model is that it’s easy to lose sight of the bigger picture of the forest through the trees.
React and technical problems
React also made implementing complex interactive features easier compared to existing solutions at the time.
Its declarative model results in an n-ary tree data structure that gets fed into a platform-specific renderer like react-dom. As we scaled up teams and reached for off-the-shelf packages, this tree structure tended to get deep very quickly.
Since its rewrite in 2016, React has proactively addressed the technical problem of optimizing large, deep trees, that need to be processed on end-user hardware.
Down the wire, on the other side of the screen, users also have limited time and attention. Expectations are rising, while attention spans shrinking. Users don’t care about frameworks, rendering architectures, or state management. They want to do what needs to get done without friction. Another constraint - be fast and don’t make them think.
As we’ll see, many of the best practices recommended in the next-gen React (and React-flavoured) frameworks mitigate the effects of dealing with deep component trees processed purely on end-user CPUs, as performance concerns become more pressing.
Revisiting the great divide
Up until now the tech industry has been full of pendulum swings across different axes, like centralization vs. decentralization of services and thin vs. thick clients.
We’ve swung from thick desktop clients, to thin with the rise of the web. And back to thick again with the rise of mobile computing and SPAs. Where the foundational mental model of React today is rooted in this thick client-side approach.
This shift created a division between “front of the frontend” developers, well versed in CSS, interaction design, HTML, and accessibility patterns, and “back of the frontend” on the other hand, as we migrated to the client during the frontend backend split.
In the React ecosystem, the pendulum is swinging back somewhere in the middle as we try to reconcile the best of both worlds, where much of the “backend for frontend” style code migrates back to the server.
From “the view in MVC” to application architecture
In large organizations, some percent of engineers work as part of a platform that advocate and bake in architectural best practices into proprietary frameworks. These kind of developers enable the rest to leverage their limited time and attention to the things that bring home the bacon - like building new features.
One effect of being constrained by limited time and attention is that we’ll often default to what feels easiest. So we want these positive constraints that keep us on the right path and make falling into a pit of success easy.
A big part of this success is being fast. Which often means reducing the amount of code that needs to load and run on end-user devices. With the principle only download and run what is necessary.
When we are limited to a purely client-only paradigm, this is hard to adhere to. Bundles end up including data-fetching, processing, and formatting libraries (e.g., moment) that could live off the main thread.
This is shifting in frameworks like Remix and Next where React’s unidirectional data flow extends up to the server, where the simple request-response mental model of an MPA combines with the fine-grained interactivity of an SPA.
The journey back to the server
Let’s now understand the optimizations we’ve applied to this client-only paradigm over time, which required reintroducing servers for better performance. This context will help us understand React frameworks where the server evolves to become a first-class citizen.
Here’s a straightforward approach to serving client-rendered frontends - the blank HTML page with many script tags:
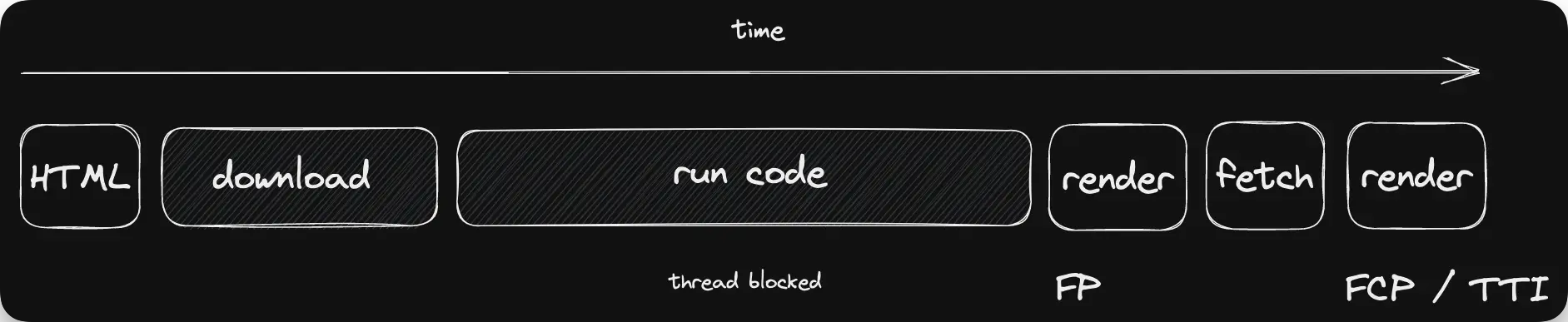
The benefit of this approach is the fast TTFB, simple operational model, and decoupled backend. Combined with React’s programming model, this combination simplifies many people problems.
But we quickly encounter technical problems because the onus is placed on user hardware to do everything. We must wait until everything is downloaded and run, and then fetch from the client before anything useful is displayed.
As code accumulates over the years, there’s only one place for it to go. Without careful performance management, this can result in show-stoppingly slow applications.
Enter server side rendering
Our first step back to the server was to try and address these slow start-up times.
Rather than responding to the initial document request with a blank HTML page, we immediately start fetching data on the server, then render the component tree to HTML and respond with that.
In the context of a client-rendered SPA, SSR is like a trick to show at least something initially while the Javascript loads. Instead of a blank white screen.

SSR can improve perceived performance, especially for content-heavy pages. But it comes with an operational cost, and can degrade user experiences for highly interactive pages - as TTI is pushed out further.
This is known as the “uncanny valley’ where users see stuff on the page and try to interact with it, but the main thread is locked. The problem still being too much Javascript saturating a single thread.
The need for speed - more optimizations
So SSR can speed things up, but isn’t a silver bullet.
There’s also the inherent inefficiency of doing the work twice to render on the server and replaying everything once React takes over on the client.
A slower TTFB means the browser has to wait patiently after requesting a document to receive the head element in order to know what assets to start downloading.
This is where streaming comes into play, which brings more parallelism into this picture.
We can imagine if ChatGPT showed a spinner until the entire reply was complete. Most people would think it’s broken and close the tab. So we show whatever we can sooner rather than later, by streaming data and content into the browser as it completes.
Streaming for dynamic pages is a way start fetching on the server as early as possible. And also get the browser to start downloading assets at the same time, all in parallel. This is much faster than the previous diagram above, where we wait until everything has been fetched and everything rendered before sending down the HTML with data.
More on streaming
This streaming technique depends on the backend server stack or edge run-times being able to support streaming data.
For HTTP/2, HTTP streams (a feature that allows sending multiple requests and responses concurrently) are used, while for HTTP/1, the Transfer-Encoding: chunked mechanism is used which enables sending data in smaller, separate chunks.
Modern browsers come with the Fetch API built-in, which can consume a fetch response as a readable stream.
The body property of the response is a readable stream that allows the client to receive data chunk by chunk as they become available from the server. Rather than waiting for all the chunks to finish downloading at once.
This approach requires setting up the ability to send streamed responses from the server and read them back on the client, necessitating close collaboration between the client and server.
There are some nuances to streaming worth noting, such as caching considerations, handling HTTP status codes and errors, and what the end-user experience looks like in practice. Where there’s a tradeoff between layout shifts and fast TTFB.
Up to this point, we’ve taken our client-rendered tree and improved its startup time by fetching early on the server while flushing HTML early to parallelize the fetching of data on the server with the downloading of assets on the client, simultaneously.
Let’s now turn our attention to fetching and mutating data.
Data fetching constraints in React
One constraint of a hierarchical component tree, where “everything is a component,” is that nodes often have multiple responsibilities, like initiating fetches, managing loading states, responding to events, and rendering.
This usually means we need to traverse the tree to know what to fetch.
In the early days of these optimizations, generating the initial HTML with SSR often meant manually traversing the tree on the server. This involved dipping into React internals to collect up all data dependencies, and fetching sequentially as the tree was traversed.
On the client, this “render then fetch” sequence leads to loading spinners coming and going alongside layout shifts, as the tree is traversed creating a sequential network waterfall.
So we want a way to fetch data and code in parallel without having to traverse the tree top to bottom every time.
Understanding Relay
It’s useful to understand the principles behind Relay and how it tackles these challenges at scale at Facebook. These concepts will help us understand the patterns we’ll see later.
Components have data dependencies co-located
In Relay, components declaratively define their data dependencies as GraphQL fragments.
The main distinction from something like React Query, which also features co-location, is that components don’t initiate fetches.
Tree traversal occurs during build time
The Relay compiler goes through the component tree, gathering each component’s data needs and generates an optimized GraphQL query.
Typically, this query gets executed at route boundaries (or specific entry points) at runtime. Allowing both component code and server data to load in parallel, as early as possible.
Co-location supports one of the most valuable architectural principles to aim for - the ability to delete code. By removing a component, its data requirements are also removed, and the query will no longer include them.
Relay mitigates many trade-offs associated with dealing with a large tree data structure when fetching resources over the network.
However, it can be complex, requires GraphQL, a client-side run time, and an advanced compiler to reconcile the DX attributes while staying performant.
Later we’ll see how React Server Components follow a similar pattern for the wider React ecosystem.
The next best thing
What’s another way to avoid traversing the tree when fetching data and code, without taking on all this?
This is where nested routes on the server found in frameworks like Remix and Next come into play.
The initial data dependencies of components can typically be mapped to URLs. Where nested segments of the URL map to component sub-trees. This mapping enables frameworks to identify the data and component code needed for a particular URL in advance.
For example in Remix, sub-trees can be self-contained with their own data requirements, independent of parent routes, where the compiler ensures that nested routes load in parallel.
This encapsulation also affords graceful degradation by providing separate error boundaries for independent sub-routes. It also allows frameworks to eagerly preload data and code by looking at the URL for faster SPA transitions.
More parallelization
Let’s delve into how Suspense, concurrent mode, and streaming enhance the data fetching patterns we’ve been exploring.
Suspense allows a sub-tree to fall back to displaying a loading UI when data is unavailable, and resume rendering when it’s ready.
It’s a nice primitive that allows us to declaratively express asynchronicity in an otherwise synchronous tree. This enables us to parallelize fetching resources with rendering at the same time.
As we saw when we introduced streaming before, we can start sending stuff sooner without waiting around for everything to finish before rendering.
In Remix this pattern is expressed with the defer function in route-level data loaders:
// Remix APIs encourage fetching data at route boundaries
// where nested loaders fetch in parallel
export function loader ({ params }) {
// not critical, start fetching, but don't block rendering
const productReviewsPromise = fetchReview(params.id)
// critical to display page with this data - so we await
const product = await fetchProduct(params.id)
return defer({ product, productReviewsPromise })
}
export default function ProductPage() {
const { product, productReviewsPromise } = useLoaderData()
return (
<>
<ProductView product={product}>
<Suspense fallback={<LoadingSkeleton />}>
<Async resolve={productReviewsPromise}>
{reviews => <ReviewsView reviews={reviews} />}
</Async>
</Suspense>
</>
)
}RSCs in Next afford a similar data fetching pattern using async components on the server that can await critical data.
// Example of similar pattern in a server component
export default async function Product({ id }) {
// non critical - start fetching but don't block
const productReviewsPromise = fetchReview(id)
// critical - block rendering with await
const product = await fetchProduct(id)
return (
<>
<ProductView product={product}>
<Suspense fallback={<LoadingSkeleton />}>
{/* Unwrap promise inside with use() hook */}
<ReviewsView data={productReviewsPromise} />
</Suspense>
</>
)
}
The principle here is to fetch data on the server as early as possible. Ideally with loaders and RSCs close to the data source.
To avoid any unnecessary waiting, we stream less critical data, so the page can progressively load in stages - which is made easy with Suspense.
RSCs by themselves don’t have an inherent API that promotes data fetching at route boundaries. This can result in sequential network waterfalls if not carefully structured. This is one line frameworks need to walk between baking in best practices, versus enabling greater flexibility with more surface area for foot-guns.
It’s worth noting that when RSCs are deployed close to data, the impact of sequential waterfalls is greatly reduced compared to client side waterfalls. Highlighting these patterns underscores that RSCs require a higher level framework integration with a router that can map URLs to specific components.
Before we dive more into RSCs, let’s take a minute to understand the other half of the picture.
Data mutations
A common pattern of managing remote data in a client only paradigm, is inside some sort of normalized store (e.g a Redux store).
In this model, mutations often optimistically update the client cache in memory, and then send a network request to update the remote state on the server.
Managing this manually has historically involved a lot of boilerplate, and is prone to errors with all the edge cases we discussed in The new wave of React state management.
The advent of hooks led to tools like Redux RTK and React Query that specialize in managing all those edge cases. In a client-only paradigm, this requires shipping code down the wire to handle these concerns, where values are propagated via React context. On top of being easy to create inefficient sequential i/o operations as the tree is traversed.
So how does this existing pattern change when React’s unidirectional data flow extends up to the server?
A significant amount of this “back of the frontend” style code moves to the actual backend.
Below is an image taken from Data Flow in Remix, which illustrates the shift frameworks are making toward the request-response model found in MPA (multi-page application) architectures.
This shift is a departure from the model of having everything handled purely by the client to one where the server plays a more significant role.

You can also check out The Web’s Next Transition for a deeper dive into this transition.
This pattern is also extends to RSCs with the experimental “server action functions” we’ll touch on in a bit. Where the unidirectional data flow of React extends into the server, in a simplified request-response model with progressively enhanced forms.
Getting to rip out code from the client is a nice benefit from this approach. But the primary benefit is simplifying the data management mental model, which in turn, simplifies a lot of existing client code.
Understanding React Server Components
Up until this point we’ve leveraged servers as a way to optimize the limitations of a purely client side approach.
Today our mental model of React is deeply rooted as a client-rendered tree running on users machines. RSCs introduce the server as a first-class citizen, rather than an after-the-fact optimization. React evolves to grow a powerful outer layer, where the backend becomes embedded into the component tree.
This architectural shift causes many changes to existing mental models of what a React application is, and how it’s deployed.
The two most obvious effects is the affordance of the optimized data loading patterns we’ve been talking about so far, and automatic code splitting.
In the second half of Building and delivering frontends at scale we touched on some key problems at scale like dependency management, internationalization and optimized A/B testing.
When limited to a purely client side environment these problems can be tricky to solve optimally at scale. RSCs alongside the many of the features of React 18, provide a set of primitives that frameworks can use to solve many of these problems.
One mind-bending mental model change is the fact that client components can render server components.
This is useful to help visualize a component tree with RSCs, as they are connected all the way down the tree. With “holes” where client components snap in to provide client side interactivity.
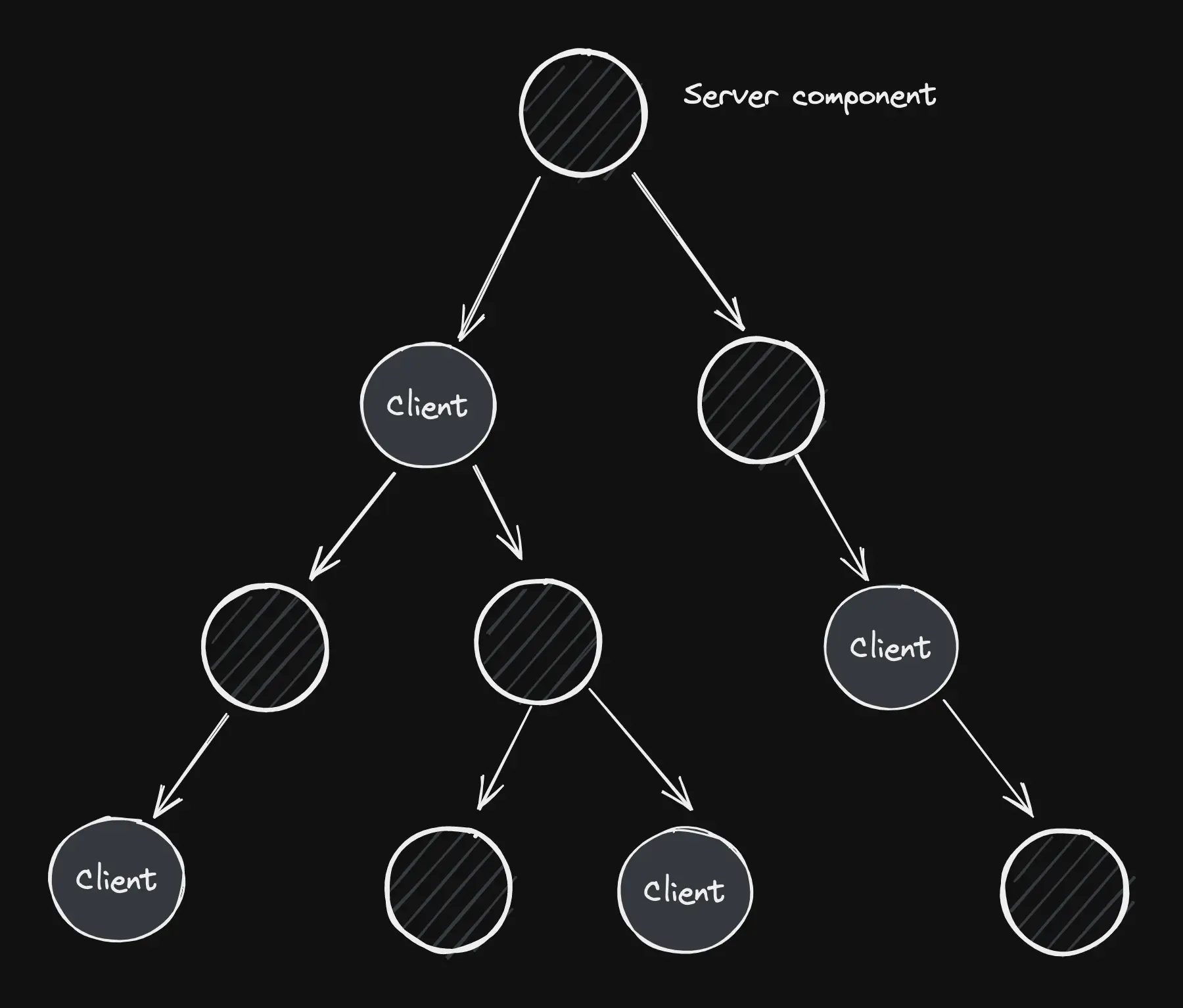
Extending the server down the component tree is powerful because we can avoid sending unnecessary code down the wire. And unlike users hardware, we have much more control of server resources.
The roots of the tree are planted in the server, the trunk extends across the network, where leaves are pushed out to client components that run on user hardware.
This expanded model requires us to be aware of the serialization boundaries in component trees, which are marked with the 'use client' directive. It also re-emphases the importance of mastering composition, to allow RSCs to pass through children or slots in client components to render as deep into the tree as needed.
Server action functions
As we migrate areas of the frontend back to servers, many innovative ideas are being explored. These offer glimpses into the future of a seamless blend between client and server.
What if we could get the benefits of co-location with components, without needing a client-side library, GraphQL, or worrying about inefficient waterfalls at runtime?
An example of server functions can be seen in the React-flavoured meta-framework Qwik city. With similar ideas are being explored and discussed in React (Next) and Remix.
The Wakuwork repo also provides a proof of concept for implementing React server “action functions” for data mutations.
As with any experimental approach, there are trade-offs to consider. When it comes to client-server communication, there are concerns around security, error handling, optimistic updates, retries, and race conditions. Which we’ve learnt that if not managed by a framework, often just go unaddressed.
This exploration also emphasizes the fact that achieving the best UX combined with the best DX often entails advanced compiler optimizations that increase the complexity under the hood.
Conclusion
Software is a just a tool to help accomplish something for people - many programmers never understood that. Keep your eyes on the delivered value, and don’t over focus on the specifics of the tools — John Carmack
As the React ecosystem evolves beyond a client-only paradigm, it’s important to understand the abstractions below and above us.
Gaining a clear understanding of the fundamental constraints within which we operate allows us to make better-informed tradeoffs.
With each pendulum swing, we gain new knowledge and experience to integrate into the next round of iteration. Where the merits of previous approaches remain valid. As always, it’s a tradeoff.
What’s great is that frameworks are increasingly providing more levers to empower developers to make finer-grained tradeoffs for specific situations. Where optimized user experience meets optimized developer experience, and where the simple model of MPAs meets the rich model of SPAs in a hybrid blend of client and server.